
Em um artigo passado, detalhamos a lógica por traz da análise de regressão, o instrumento utilizado pela econometria para analisar a relação entre duas ou mais variáveis. Nesse artigo iremos formalizar o modelo geral de uma análise de regressão. Para começar, será analisado um modelo com apenas duas variáveis, Y e X.
AVISO: Até agora não foi necessário grandes conhecimentos em demais disciplinas, mas para formalizar o modelo de regressão é preciso uma certa carga de conhecimento em inferência e probabilidade, principalmente no que tange a ideia de variável aleatória. Também será exigido conhecimento sobre funções matemáticas.
Até agora definimos a análise de regressão como o estudo de uma variável em função de outras variáveis, mas como isso é justificado probabilisticamente? Temos o análise de regressão como o estudo de como uma variável varie em função da média de outras variáveis. Trocando por miúdos, é analise de qual o valor esperado de Y dado um valor de X, em termos probabilísticos, temos então uma probabilidade condicionada, expressa como:
Essa ideia de probabilidade condicionada significa entre outras palavras que a média de Y varia conforme a média da variável condicionante X. Para entender com mais precisão, vamos remeter a um exemplo trazido no livro do autor Gujarati, que traz uma tabela que relaciona a renda de uma série de famílias e a suas despesas com consumo, visando estudar como o consumo varia em função da renda.
A tabela (adaptada) é a seguinte:
Como visto, existem categorias de renda para X, que vão de 80 a 260, e para cada nível de renda fixada existe um grupo de valores de consumo, cada um desses valores é uma amostra. Para entender, observe que para renda igual a 80 existem 5 amostras, uma com 55, uma com 60, uma 65, uma com 70 e uma 75. Esses 5 são indivíduos com renda igual a 80 que foram perguntados o quanto gastam com consumo.
Se plotarmos isso graficamente, observaremos o seguinte comportamento:
O que se enxerga a uma primeira vista? Uma clara relação positiva entre as duas variáveis, dado que a medida que a renda se eleva, o consumo se eleva. Isso é uma visão óbvia, mas como analisar isso com o rigor probabilístico? Através de um modelo de regressão. Essa análise de regressão se baseia em analisar como o valor esperado de Y varia em função do valor de X, ou seja, o grande objetivo é estudar qual valor esperado de Y dado o valor fixado de X.
A esperança matemática condicionada é a mesma coisa, sendo dada por: Para exemplificar, vamos calcular para o primeiro grupo com renda igual a 80 dólares, o valor esperado de Y é igual a média dos valores Y para X = 80, ou seja: Lê-se "o valor esperado de Y dado X igual a 80 é igual a 65". Qual o significado prático disso? Significa que em média quem tem a renda igual a 80 dólares consome cerca de 50 dólares.
Aplicando esse mesmo cálculo para todos os grupos de renda chegamos na seguinte tabela:
Como interpretar esses resultados? Observe que a medida em que a renda aumenta, a média de despesas de consumo aumenta, isso aponta uma relação positiva, entre as duas variáveis. A grande questão da análise de regressão é criar uma função matemática representativa dessa relação, relembrando o formato funcional que estabelecemos para a regressão:
Agora que calculamos os valores esperados de Y para cada renda, podemos demonstrar graficamente essa função matemática representativa, sendo dada por: Através do cálculo das médias condicionadas conseguimos construir uma função que represente essa relação entre renda e consumo, e o que ela nos diz? Primeiro, que essa relação é positiva, segundo que há uma certa significância dessa relação observando a inclinação da reta, isso será analisado mais a fundo ao se estudar a ideia de parâmetros. e terceiro, essa relação é linear.
Essa função é chamada de função de regressão populacional que pode ser definida como a reta que passa por todas as médias condicionadas de Y, para melhor enxergar, vamos plota-la frente ao gráfico de dispersão.
Descobrir a
função de regressão populacional é a grande questão da econometria, pois descobrindo-a podemos estudar a fundo e com rigor a relação entre duas variáveis e sua magnitude. Descobrir essa relação é essencialmente descobrir a forma funcional, sabendo que:
Essa formato funcional f(Xi) pode assumir uma série de formatos, dependendo da dispersão dos dados, alguns exemplos são:
Cada um desses modelos se encaixa melhor conforme os dados são dispersos, por exemplo, no caso vimos uma óbvia tendência linear, o que é razoável supor que a Função de Regressão Populacional assuma um formato linear, mas o mesmo modelo não seria eficiente em um caso de óbvia tendência exponencial, como por exemplo:
Nesse caso não é prudente aplicar um modelo linear para analisar, sendo mais recomendado uma regressão exponencial. Mas ao longo do curso será trabalhado somente a hipótese da linearidade, que é a suposição simples de que a relação entre duas variáveis pode ser expressa em uma reta linear. Isso será melhor desenvolvido no próximo artigo onde será apresentado o
modelo de regressão linear simples. Portanto, o grande objetivo agora se torna encontrar o formato funcional da função de regressão populacional. Descobrindo esse formato funcional podemos estudar a relação e o seu grau.;
Acontece que antes de descobrir como se "achar" a função de regressão populacional é preciso detalhar um ponto sobre a função de regressão populacional.
Como visto em artigo anterior, a análise de regressão não busca (e nem poderia) uma previsão exata, portanto precisamos definir uma modelagem estocástica, afirmando que a função de regressão populacional não é igual aos valores observados, essencialmente:
Essas diferenças são chamados de
erros ou
componente estocástico, que representa a diferença entre os valores previstos e os valores, observados, tal que:
Para entender o componente estocástico, vamos retomar o exemplo da tabela:

Observe que para X = 80 a Função de Regressão Populacional prevê que a faixa de "consumo" deve ser igual a 65, entretanto, há 4 amostras que divergem desse valor. O erro de cada amostra seria a diferença entre o valor de consumo previsto para cada faixa de renda e a renda específica, se representarmos os erros, nessa tabela, você observará os seguintes erros de previsão:
Esse componente de erro é um ponto essencial para a análise de regressão, mais adiante será observado que ele será o componente essencial para formular o modelo de análise de regressão.
Por ora, basta saber que o modelo de regressão tem um componente de erro que diferencia o modelo de regressão dos fatos observados, tal que:
Tendo em mente a ideia de erros estocásticos podemos então desenvolver a maneira formal de se obter a função regressão populacional.
Como se observa, trata-se de uma função de regressão populacional, esse termo populacional diz respeito a uma situação onde temos acesso a todas as amostras de uma determinada população, ocorre que isso não é uma perspectiva realista, visto que geralmente somente se tem acesso a uma (ou mais) amostras. Portanto, temos que agora trabalhar com um função de regressão amostral, uma aplicação da análise de regressão partindo-se da ideia de que não se tem acesso a todos os dados da população. Com isso surge uma questão, cada amostra terá uma função de regressão diferente, então como podemos saber qual a função mais adequada? A função de regressão amostral se baseia na utilização de um estimador, quando tenta-se estimar um valor para a média condicionada de Y dado X, esse estimador é representado por um Y estimado, tal que:
Observe que há também um componente de erro, quando tratamos de uma
função amostral chamamos esse componente de erro de
resíduo da regressão. Adiante será observado que ele será o fundamento de avaliação de um modelo, pois quanto maior o erro, menos preciso ele é.
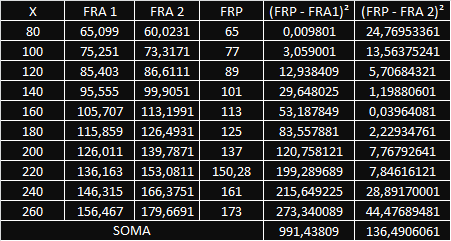
Para demonstrar a diferença entre FRA e FRP e a relevância dos erros, vamos tomar a amostra da tabela que utilizamos no exemplo e dividir em duas, tendo duas amostras diferentes, cada uma com doze observações:

Observe que cada uma das duas apresentam médias condicionadas diferentes, tal que se plotarmos as duas
funções de regressão amostral em um gráfico (não entraremos em detalhes sobre como chegamos nelas nele nesse artigo) obtemos:
Qual das duas é mais precisa? Para saber disso basta enxergar qual a que mais se aproxima da função de regressão populacional, para isso comparamos os valores com o valor obtido pela FRP, visualizando:
A primeira vista a segunda função de regressão é mais próxima, isso é real? Para confirmar vamos calculara diferença geométrica pela tabela:
Com isso fica claro a influência da amostra escolhida, o objetivo agora torna-se mais óbvio, encontrar a
Função de Regressão Populacional escolhendo a melhor (mais próxima)
Função de Regressão Amostral. Como ficará claro, o critério para escolher a função de regressão amostral mais adequada são os erros amostrais, o elemento estocástico.
A ferramenta que será utilizada para chegar a esse resultado é a inferência estatística.
Uma vez compreendido a essência do Modelo de Regressão Simples, no próximo artigo, iremos então desenvolver o principal instrumento de análise de regressão que será utilizada na econometria: O Modelo de Regressão Linear Simples.
Bibliografia:
GUJARATI, Damodar N; PORTER, Dawn C. Basic Econometrics. 5ª Edição. New York. The McGraw-Hill, 2008.




















Gostou do conteúdo? Deixe seu comentário! Não gostou? Deixa também, queremos ouvir sua opinião!
ResponderExcluirSiga nossa página no Instagram: @agenteracional